
Cos'è il Machine Learning?
Il machine learning è una forma di AI che permette a un sistema di imparare dai dati piuttosto che attraverso la programmazione esplicita. Tuttavia, il machine learning non è un processo semplice. Poiché gli algoritmi assimilano i dati di addestramento, è possibile produrre modelli più precisi basati su tali dati. Un modello di machine learning è l'output generato quando si addestra il proprio algoritmo di machine learning con i dati. Dopo l'addestramento, quando si fornisce un input a un modello, verrà generato un output. Ad esempio, un algoritmo predittivo creerà un modello predittivo. Poi, quando si forniscono i dati al modello predittivo, si riceverà una previsione basata sui dati che hanno addestrato il modello.

Data Science - Apprendimento Iterativo
Il machine learning consente ai modelli di addestrarsi sui dataset prima di essere distribuiti. Alcuni modelli di machine learning sono online e continui. Questo processo iterativo dei modelli online porta ad un miglioramento dei tipi di associazioni effettuate tra gli elementi di dati. A causa della loro complessità e portata, tali modelli e associazioni avrebbero potuto facilmente essere ignorati dall'osservazione umana. Dopo che un modello è stato addestrato, può essere utilizzato in tempo reale per l'apprendimento dai dati. I miglioramenti dell'accuratezza sono il risultato del processo formativo e dell'automazione che fanno parte del machine learning.
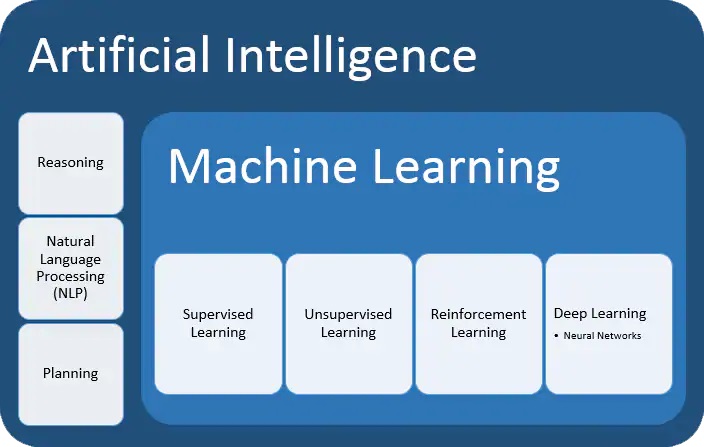
Approcci al Machine Learning
Le tecniche di machine learning sono necessarie per migliorare l'accuratezza dei modelli predittivi. A seconda della natura del problema aziendale che si deve affrontare, ci sono approcci diversi basati sul tipo e sul volume dei dati. In questa sezione parleremo delle categorie di machine learning.
Apprendimento supervisionato
L'apprendimento supervisionato generalmente inizia con una serie stabilita di dati e una certa comprensione di come i dati siano classificati. L'apprendimento supervisionato è destinato a trovare modelli nei dati che possono essere applicati a un processo di analytics. Questi dati hanno funzioni etichettate che definiscono il significato dei dati. Ad esempio, è possibile creare un'applicazione di machine learning che distingua tra milioni di animali, sulla base di immagini e descrizioni scritte.
Apprendimento non supervisionato
L'apprendimento non supervisionato viene utilizzato quando il problema richiede una quantità enorme di dati non etichettati. Ad esempio, le applicazioni di social media, come Twitter, Instagram e Snapchat, hanno tutti grandi quantità di dati non etichettati. Capire il significato dietro a questi dati richiede algoritmi che classificano i dati in base ai modelli o ai cluster rilevati. L'apprendimento senza supervisione conduce un processo iterativo, analizzando i dati senza intervento umano. Viene utilizzato con la tecnologia di rilevamento di spam nelle email. Ci sono troppe variabili nelle email spam e nelle email legittime per far sì che un analista riesca a taggare un certo volume di email indesiderate. Vengono, invece, applicati classificatori di machine learning, basati su clustering e associazione, per identificare email indesiderate.
Apprendimento per rinforzo
L'apprendimento per rinforzo è un modello di apprendimento comportamentale. L'algoritmo riceve un feedback dall'analisi dei dati, guidando l'utente al miglior risultato. L'apprendimento per rinforzo differisce dagli altri tipi di apprendimento supervisionato, perché il sistema non è addestrato con il dataset di esempio. Piuttosto, il sistema impara attraverso la prova e l'errore. Quindi, una sequenza di decisioni di successo determinerà il rafforzamento del processo, perché riesce subito a risolvere il problema al meglio.
Deep Learning
Il deep learning è un metodo specifico di machine learning che incorpora reti neurali in strati successivi per imparare dai dati in modo iterativo. Il deep learning è particolarmente utile quando si cerca di apprendere i modelli da dati non strutturati. Le reti neurali complesse di deep learning sono progettate per emulare il funzionamento del cervello umano, così i computer possono essere addestrati ad occuparsi di astrazioni e problemi mal definiti. Il bambino di cinque anni in media può riconoscere facilmente la differenza tra il volto del suo insegnante e il volto del sorvegliante per l'attraversamento. Al contrario, il computer deve fare un sacco di lavoro per capire chi è chi. Le reti neurali e il deep learning sono spesso utilizzati nelle applicazioni di riconoscimento delle immagini, di linguaggio e di visione artificiale.
I big data nell'ambito del machine learning
Il machine learning richiede che venga applicata la serie corretta di dati a un processo di apprendimento. Un'organizzazione non deve necessariamente disporre di big data per utilizzare le tecniche di machine learning; tuttavia, i big data possono contribuire a migliorare la precisione dei modelli di machine learning. Con i big data è ora possibile virtualizzare i dati, in modo che possano essere memorizzati nel modo più efficiente ed economicamente conveniente, sia on premise che sul cloud. Inoltre, i miglioramenti della velocità di rete e dell'affidabilità hanno rimosso altre limitazioni fisiche associate alla gestione di enormi quantità di dati a una velocità accettabile. Aggiungi a questo l'impatto dei cambiamenti nel prezzo e nella complessità della memoria del computer e ora è possibile immaginare come le aziende possano utilizzare efficacemente i dati in modi che sarebbero stati inconcepibili solo cinque anni fa.
Come applicare il machine learning alle esigenze di business
Il machine learning offre un valore potenziale alle aziende che cercano di sfruttare i big data e le aiuta a capire meglio i sottili cambiamenti del comportamento, delle preferenze o della soddisfazione del cliente. I business leader stanno iniziando a riconoscere che non tutto ciò che accade all'interno delle loro organizzazioni e settori può essere compreso mediante una query. Non sono le domande che conosci; sono gli schemi nascosti e le anomalie non evidenti nei dati che possono aiutarti o danneggiarti.
Vantaggi nell'utilizzo del machine learning
Il vantaggio del machine learning è che è possibile sfruttare algoritmi e modelli per prevedere i risultati. Lo scopo è quello di garantire che i data scientist utilizzino i migliori algoritmi durante il lavoro, con l'acquisizione di dati più appropriati (precisi e puliti) e l'utilizzo dei migliori modelli di esecuzione. Se tutti questi elementi si riuniscono, è possibile addestrare continuamente il modello e imparare dai risultati apprendendo dai dati. L'automazione di questo processo di creazione, addestramento e test del modello porta a previsioni accurate per sostenere il cambiamento di business.
FONTE: IBM
Tutti i diritti riservati - Tutti i marchi sono di proprietà delle rispettive società
Cos'è il Machine Learning?
Il machine learning è una forma di AI che permette a un sistema di imparare dai dati piuttosto che attraverso la programmazione esplicita. Tuttavia, il machine learning non è un processo semplice. Poiché gli algoritmi assimilano i dati di addestramento, è possibile produrre modelli più precisi basati su tali dati. Un modello di machine learning è l'output generato quando si addestra il proprio algoritmo di machine learning con i dati. Dopo l'addestramento, quando si fornisce un input a un modello, verrà generato un output. Ad esempio, un algoritmo predittivo creerà un modello predittivo. Poi, quando si forniscono i dati al modello predittivo, si riceverà una previsione basata sui dati che hanno addestrato il modello.
Approcci al Machine Learning
Le tecniche di machine learning sono necessarie per migliorare l'accuratezza dei modelli predittivi. A seconda della natura del problema aziendale che si deve affrontare, ci sono approcci diversi basati sul tipo e sul volume dei dati. In questa sezione parleremo delle categorie di machine learning.
Apprendimento supervisionato
L'apprendimento supervisionato generalmente inizia con una serie stabilita di dati e una certa comprensione di come i dati siano classificati. L'apprendimento supervisionato è destinato a trovare modelli nei dati che possono essere applicati a un processo di analytics. Questi dati hanno funzioni etichettate che definiscono il significato dei dati. Ad esempio, è possibile creare un'applicazione di machine learning che distingua tra milioni di animali, sulla base di immagini e descrizioni scritte.
Apprendimento non supervisionato
L'apprendimento non supervisionato viene utilizzato quando il problema richiede una quantità enorme di dati non etichettati. Ad esempio, le applicazioni di social media, come Twitter, Instagram e Snapchat, hanno tutti grandi quantità di dati non etichettati. Capire il significato dietro a questi dati richiede algoritmi che classificano i dati in base ai modelli o ai cluster rilevati. L'apprendimento senza supervisione conduce un processo iterativo, analizzando i dati senza intervento umano. Viene utilizzato con la tecnologia di rilevamento di spam nelle email. Ci sono troppe variabili nelle email spam e nelle email legittime per far sì che un analista riesca a taggare un certo volume di email indesiderate. Vengono, invece, applicati classificatori di machine learning, basati su clustering e associazione, per identificare email indesiderate.
Apprendimento per rinforzo
L'apprendimento per rinforzo è un modello di apprendimento comportamentale. L'algoritmo riceve un feedback dall'analisi dei dati, guidando l'utente al miglior risultato. L'apprendimento per rinforzo differisce dagli altri tipi di apprendimento supervisionato, perché il sistema non è addestrato con il dataset di esempio. Piuttosto, il sistema impara attraverso la prova e l'errore. Quindi, una sequenza di decisioni di successo determinerà il rafforzamento del processo, perché riesce subito a risolvere il problema al meglio.
Deep Learning
Il deep learning è un metodo specifico di machine learning che incorpora reti neurali in strati successivi per imparare dai dati in modo iterativo. Il deep learning è particolarmente utile quando si cerca di apprendere i modelli da dati non strutturati. Le reti neurali complesse di deep learning sono progettate per emulare il funzionamento del cervello umano, così i computer possono essere addestrati ad occuparsi di astrazioni e problemi mal definiti. Il bambino di cinque anni in media può riconoscere facilmente la differenza tra il volto del suo insegnante e il volto del sorvegliante per l'attraversamento. Al contrario, il computer deve fare un sacco di lavoro per capire chi è chi. Le reti neurali e il deep learning sono spesso utilizzati nelle applicazioni di riconoscimento delle immagini, di linguaggio e di visione artificiale.
I big data nell'ambito del machine learning
Il machine learning richiede che venga applicata la serie corretta di dati a un processo di apprendimento. Un'organizzazione non deve necessariamente disporre di big data per utilizzare le tecniche di machine learning; tuttavia, i big data possono contribuire a migliorare la precisione dei modelli di machine learning. Con i big data è ora possibile virtualizzare i dati, in modo che possano essere memorizzati nel modo più efficiente ed economicamente conveniente, sia on premise che sul cloud. Inoltre, i miglioramenti della velocità di rete e dell'affidabilità hanno rimosso altre limitazioni fisiche associate alla gestione di enormi quantità di dati a una velocità accettabile. Aggiungi a questo l'impatto dei cambiamenti nel prezzo e nella complessità della memoria del computer e ora è possibile immaginare come le aziende possano utilizzare efficacemente i dati in modi che sarebbero stati inconcepibili solo cinque anni fa.
Come applicare il machine learning alle esigenze di business
Il machine learning offre un valore potenziale alle aziende che cercano di sfruttare i big data e le aiuta a capire meglio i sottili cambiamenti del comportamento, delle preferenze o della soddisfazione del cliente. I business leader stanno iniziando a riconoscere che non tutto ciò che accade all'interno delle loro organizzazioni e settori può essere compreso mediante una query. Non sono le domande che conosci; sono gli schemi nascosti e le anomalie non evidenti nei dati che possono aiutarti o danneggiarti.
Vantaggi nell'utilizzo del machine learning
Il vantaggio del machine learning è che è possibile sfruttare algoritmi e modelli per prevedere i risultati. Lo scopo è quello di garantire che i data scientist utilizzino i migliori algoritmi durante il lavoro, con l'acquisizione di dati più appropriati (precisi e puliti) e l'utilizzo dei migliori modelli di esecuzione. Se tutti questi elementi si riuniscono, è possibile addestrare continuamente il modello e imparare dai risultati apprendendo dai dati. L'automazione di questo processo di creazione, addestramento e test del modello porta a previsioni accurate per sostenere il cambiamento di business.
FONTE: IBM
Tutti i diritti riservati - Tutti i marchi sono di proprietà delle rispettive società